
So, you keep hearing these terms like big data, data science, data lake thrown around the web lately. Your friends and colleagues who used to whine about their tedious jobs cleaning, querying and moving data all day now proudly call themselves data engineers or even data scientists. Of course, our real “scientist” friends (the physicists, mathematicians, biologists and statisticians) have also changed their CVs to be called data scientists. You wonder what this data scientist thing that has been called the “sexiest job of the 21st century” is? More importantly, how do you become one?
I started my career almost a decade ago as a fresh graduate who wanted to become a C++ programmer and was distraught when I was made to work as a data analyst instead. Today, I have that title on my Linkedin and have “data” in the name of my own company.
So, I often get questions from people on this topic. This is my attempt to answer that question as I’ve interpreted it for my company, and I hope it will help others too.
It may not look obvious but “data” has been a part of human civilization for a long time. As far back as 18,000 BCE, pre-historic people were using marks on stones or bones to keep a tally of their supplies to know when their food would run out. The word itself is the plural form of the latin word “datum”, which means “(something) given”.
In this article, I will use it in the modern sense of – qualitative or quantitative information that is collected in a digital or digitizable form and can be analysed and reported to draw knowledge or wisdom from it to make better decisions.
Data can be in many forms but spreadsheets and databases are the most popular ways of storing them.
We can see that data is all around us. Researchers, businesses, and even normal folks like you and me are producing it every day. For every phone call you make, every site you visit, every sale a business makes, every statistic the government collects, a phenomenal amount of data is being generated everyday. In fact, it is estimated that with the proliferation of mobile devices, an astonishing 2.5 Quintillion bytes* of data is now produced each day. As Yoda would say, — “It surrounds us, and binds us.”
While there is a lot of data out there, this raw data is of relatively little value until it is processed. Until the last decade, storing and processing large amounts of data was really expensive and only the biggest companies and universities had the equipment (supercomputers) capable of crunching data on a large scale. But thanks to Moore’s Law, that has changed dramatically over the last decade.
We now have a lot of data stored up and have the computing power to process it. This means we need a lot of people who are good at crunching, analysing and presenting data. So the data scientist was born.
Unfortunately, this field has been overrun by hype. We have had the tech world drowned out with terms like Data Mining to Big Data, Data Science, and now Machine Learning & AI, and it’s hard to tell who does what.
I prefer the term “data science,” and the profession “data scientist” that must have been derived from it. As I’ve understood it, the fundamental task of data science is the preparation of data and the application of mathematical models to that data to get a useful outcome. The final output can either be in visual forms of dashboards and charts or as inputs to upstream software layers.
Data Science = prepare(data) => model(prepared_data) => use(model_data) => knowledge
Like anyone who has only ever put together a WordPress site isn’t quite a computer scientist, anyone who only ever used excel sum() function or written some SQL queries isn’t really a data scientist. Its a multi-disciplinary field that requires one to have the mathematical chops of a scientist or statistician, the engineering knowhow of a seasoned developer, the aesthetic knowledge of a designer, the communication skills of a leader, and the relevant domain expertise. Its easy to see that people with such skills will be very rare, what is called the “perfect data scientist” in the diagram below.
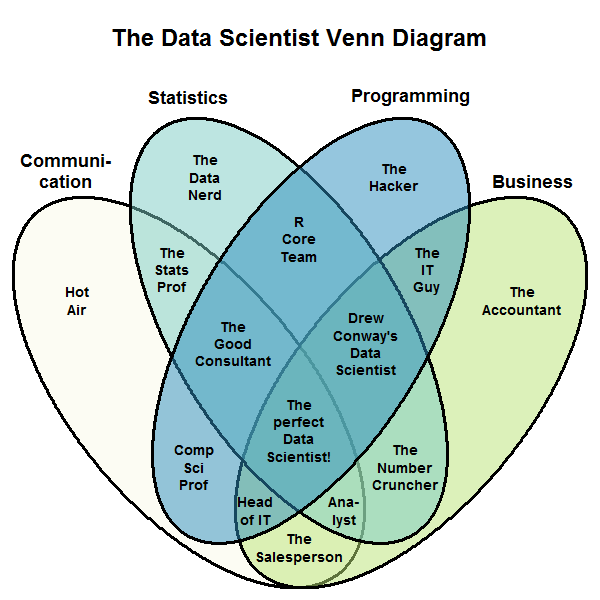
A venn diagram created by StackExchange Data Science user Stephan Kolassa
Although we might have a lot of people with the title “data scientist” around, they are not all equal. The skill required to configure cloud servers to run a 100TB Spark jobs, or to visualise a billion data points so that even non-technical people will understand it is fundamentally different from that required to be able to get an accuracy of 92% on a gradient boosting algorithm up from 75% using a weighted ensemble. In fact, I’d say mostly this is a job for a team of people that combine these different skills.
That was one of the reasons CraftData Labs was born. The aim is to bring together a team of statisticians, scientists, engineers, and designers who really know their craft to enable businesses, organisations, governments and individuals to meet their business objectives. We will not only be focussed on the technical skills of statistics, computer science and mathematics, but also on good design and communication skills. After all, the best models in the world are useless if we can’t make them consumable and actionable to the user.
If I have to define what a data scientist is at CraftData, it would be someone who is adept in statistical calculations and mathematical models, understands the rigorous scientific method, and usually has a research background. Other titles such as data engineers, web developers, UI/UX designers, front-end developers, dashboard developers, database architects, data journalists etc., serve an important but different role.
Finally, I’d say that I barely meet this definition of a data scientist myself. I certainly didn’t start out as so. But through the years of working in this discipline I do hope I’ve earned that title.
This article was first published on Medium, and adapted for Sujhaab Chautaari with permission from the author.
Author: Saurav Dhungana
Saurav is a Data Scientist and the Founder of CraftData Labs. A passionate advocate of using data to solve real-world problems, he loves creating products and solutions that help people better understand the world around them. Saurav holds a M.Sc in Communications Engineering from Aalto University, Finland.
Leave a Reply